近年、大規模言語モデル(LLM)をはじめとする生成AIの進化は目覚ましく、多くの企業がその導入を検討しています。
しかし、その一方で「不正確な情報を自信満々に生成するハルシネーション」という、大きな課題に直面しているのも事実です。
この課題を解決し、企業固有の情報を活用してAIの精度を飛躍的に向上させる技術として、今、最も注目されているのがRAG(検索拡張生成)です。
RAGは、単にインターネット上の膨大なデータから回答を生成するのではなく、企業が保有する社内ドキュメントやナレッジベースといった信頼性の高い情報源を参照することで、より正確で信頼性の高い回答を導き出します。
本記事では、このRAGの仕組みから、ナレッジ活用を最大化するための実践的な導入・運用法まで、網羅的に解説していきます。
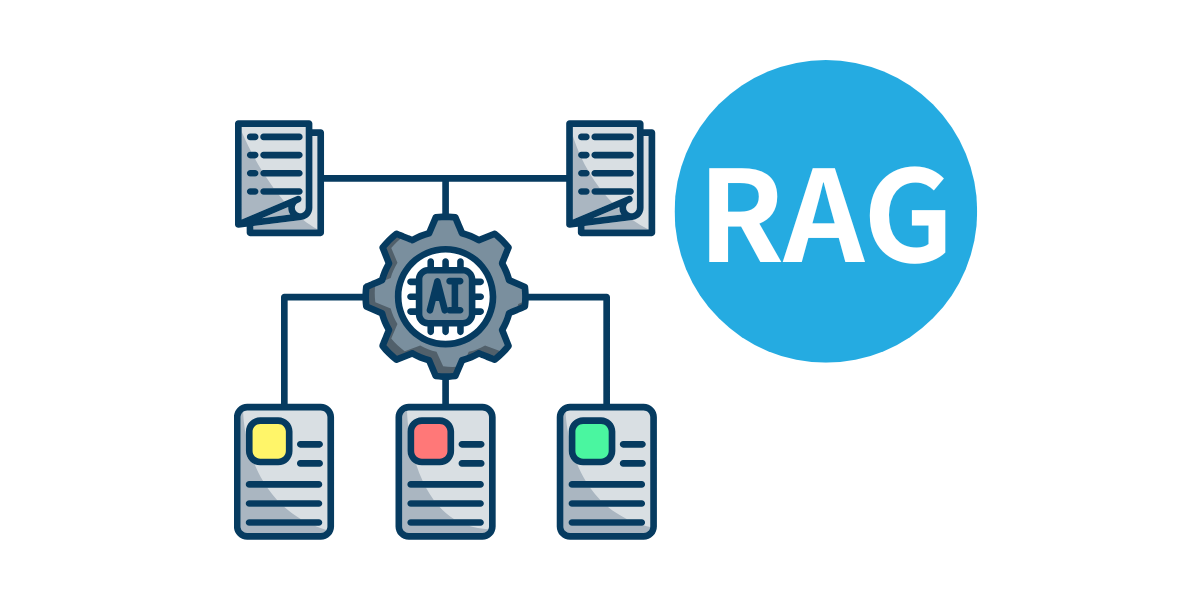
RAG(検索拡張生成)とは? 基本から仕組みを理解する
RAGは「Retrieval-Augmented Generation」の略称で、直訳すると「検索で強化された生成」となります。
これは、情報検索(Retrieval)と文章生成(Generation)という2つのプロセスを組み合わせたAI技術です。
従来のLLMが学習データのみに依存していたのに対し、RAGはリアルタイムで外部の情報源を参照する能力を持ちます。
RAGの3つのステップ
RAGの仕組みは、大きく3つのステップで構成されています。
1.情報のインデックス化(検索準備)
RAGを導入する最初のステップは、参照させたい社内ドキュメントをAIが理解できる形に変換することです。
このプロセスでは、まず膨大なドキュメントを「チャンク」と呼ばれる小さな意味のまとまりに分割します。
例えば、会議の議事録であれば、個々の議題ごとにチャンクに分けるといった作業を行います。
次に、これらのチャンクを「エンベディング」という技術を用いて、AIが理解できる数値の羅列(ベクトル)に変換します。
このベクトルは、各チャンクの意味や文脈を数学的に表現したもので、このベクトルを保存する専用のデータベースが「ベクトルデータベース」です。
このステップを完了することで、AIは社内ドキュメントを高速かつ正確に検索する準備が整います。
このインデックス化の精度が、後の回答精度を大きく左右するため、チャンクのサイズや分割方法を慎重に設計することが重要です。
2.関連情報の検索(Retrieval)
ユーザーが質問を入力すると、その質問(クエリ)もエンベディングによってベクトルに変換されます。
そして、この質問ベクトルとベクトルデータベースに保存されたドキュメントのベクトルを比較し、意味的に最も関連性の高いチャンクを高速に抽出します。
この検索方法は「セマンティック検索」と呼ばれ、キーワードの完全一致に頼る従来の検索とは異なり、「顧客からのクレーム対応」といった抽象的な質問に対しても、関連性の高いマニュアルや過去の事例を正確に見つけ出すことができます。
このセマンティック検索は、ユーザーの検索意図を深く理解するため、従来のキーワード検索では見落とされがちだった関連情報も見つけ出すことが可能です。
3.回答の生成(Generation)
最後に、検索によって抽出された関連情報(チャンク)が、ユーザーの質問とともにプロンプトとしてLLMに渡されます。
LLMは、このプロンプトに含まれる信頼性の高い情報を基に、ユーザーへの最終的な回答を生成します
これにより、LLMが架空の情報をでっち上げるハルシネーションのリスクを大幅に低減し、根拠に基づいた正確な回答を提供することが可能になります。
さらに、RAGは回答の根拠となった社内ドキュメントの出典元を明示できるため、ユーザーはAIの回答の正確性を自身で確認することができ、情報活用における信頼性が飛躍的に高まります。
なぜ今、ナレッジ活用にRAGが必要なのか? RAGがもたらす革新的メリット
RAGは単なる技術的なアプローチに留まらず、企業がナレッジ活用を進める上で多くの実用的なメリットをもたらします。
ハルシネーションの抑制と信頼性の向上
LLMの最大のリスクであるハルシネーションは、企業がAIをビジネスの基幹業務に適用する上での大きな障壁です。
RAGは、参照元を社内ドキュメントに限定することで、AIが誤った情報を生成する可能性を劇的に下げます。
これにより、従業員がAIの回答を信頼し、安心して業務に活用できるようになります。
例えば、複雑な社内規定や技術仕様に関する質問にも、出典元を明示しながら正確に回答することが可能になり、情報の信頼性が飛躍的に向上します。
この信頼性の向上は、企業内でのAIツールの利用率を高め、より広範なナレッジ活用を促進する基盤となります。
情報検索の効率化と意思決定の迅速化
RAGは、キーワード検索では見つけにくかった「探している情報」を、自然言語で尋ねるだけで見つけ出します。
これにより、マニュアルを探したり、担当者に問い合わせたりする手間が大幅に削減され、業務効率化に繋がります。
例えば、新入社員のオンボーディングや、カスタマーサポートの問い合わせ対応など、日々発生する定型的な情報検索の時間を短縮し、より付加価値の高い業務に集中できるようになります。
また、経営層が市場動向や社内データの概要を迅速に把握する意思決定支援ツールとしても機能します。
AIが迅速かつ正確に情報を集約・分析することで、データに基づいた迅速な意思決定が可能になり、企業の競争力向上に直結します。
最新情報の反映とメンテナンスの容易性
従来のAIモデルを最新の情報に対応させるには、大規模な再学習(ファインチューニング)が必要で、多大な時間とコストを要しました。
しかし、RAGは新しい社内ドキュメントを追加し、ベクトルデータベースを更新するだけで、最新の情報をAIに反映させることができます。
この手軽なメンテナンス性は、変化の激しいビジネス環境において、常に最新のナレッジベースを維持する上で非常に大きな利点となります。
この特性は、特に頻繁に情報が更新される業界(例:医療、法律、IT)において、常に最新の情報に基づいたナレッジ活用を可能にし、企業のコンプライアンス遵守やサービスの品質維持に貢献します。
RAGの導入と運用における注意点
多くのメリットがある一方で、RAGの導入と運用にはいくつかの注意点が存在します。
情報の品質とドキュメントの整備
RAGの回答精度は、参照元となる社内ドキュメントの品質に直接依存します。
誤った情報や古い情報がナレッジベースに含まれていると、AIも誤った回答を生成してしまいます。
したがって、RAGを導入する前に、社内ドキュメントの整理と標準化を行い、質の高いナレッジベースを構築することが不可欠です。
具体的には、文書の重複を排除し、情報の粒度を均一にし、メタデータ(作成日、作成者など)を付与することで、検索の精度をさらに高めることができます。
セキュリティとプライバシー保護
社内ドキュメントには、顧客情報や企業秘密といった機密情報が含まれることが少なくありません。
RAGシステムを構築する際には、誰がどの情報にアクセスできるかを厳密に制御するセキュリティ対策が不可欠です。
例えば、ユーザーの所属部署や役職に応じて参照できるドキュメントを制限する「アクセス制御リスト(ACL)」を実装することが重要です。
また、データの取り扱いに関するプライバシー保護ポリシーを明確にし、従業員や関係者への説明を徹底する必要があります。
監査ログを記録し、不審なアクセスを監視する仕組みも重要となります。
コストとメンテナンス
RAGの運用には、LLMのAPI利用料やベクトルデータベースのホスティング費用など、複数のコストが発生します。
また、参照元となるナレッジベースの更新作業など、継続的なメンテナンスも必要です。
導入前に、これらのコストとメンテナンス体制を十分に検討し、費用対効果を試算することが重要です。
特に、チャンクのサイズやエンベディングモデルの選択は、コストと精度のトレードオフに影響を与えるため、初期設計段階での慎重な検討が求められます。
RAGをナレッジ活用に活かす具体的なステップ
RAGを効果的にナレッジ活用に結びつけるための、具体的な導入ステップを解説します。
Step1:目的と対象ドキュメントの明確化
RAGを導入する前に、まず「何を解決したいのか」という目的を明確にしましょう。
例えば、「新入社員が会社規定やシステム操作方法を自己解決できる環境を整える」「カスタマーサポート担当者が過去の問い合わせ履歴から迅速に回答を見つけ出す」など、具体的なユースケースを定めます。
次に、その目的に応じて、RAGに参照させる社内ドキュメントを選定します。
この際、スモールスタートで始めることが成功の鍵となります。
Step2:技術スタックの選定
目的が明確になったら、それに適した技術スタックを選定します。
ベクトルデータベースはオープンソースのものから、クラウドサービスとして提供されているものまで多様です。
利用するLLMや、APIを統合するフレームワーク(例:LangChain, LlamaIndex)も選択肢が多数あります。
これらの技術を組み合わせることで、柔軟かつ拡張性の高いシステムを構築することが可能です。
Step3:プロトタイプ開発とテスト
選定した技術スタックを用いて、実際に小規模なプロトタイプを開発します。
この段階では、少数の社内ドキュメントをインデックス化し、想定されるユースケースでテストを行います。
質問に対する回答の精度や、システムのレスポンス速度などを評価し、本格導入に向けた課題を洗い出します。
この反復的なプロセスを経て、より洗練されたRAGシステムを構築することができます。
まとめ RAGが拓く新しいナレッジ活用の未来
いかがでしたか?
RAG(検索拡張生成)は、単なるAI技術の一つではなく、企業が保有する社内ドキュメントという貴重な資産を最大限に活用し、組織全体の知の創造と共有を加速させる強力なツールです。
RAGを適切に活用することで、ハルシネーションというAIの根本的な課題を克服し、企業の業務効率化、意思決定支援、そして従業員の生産性向上に大きく貢献します。
RAGの導入は、新しい働き方やビジネスモデルを創出する企業DXの重要な一歩となります。
技術の進化は止まりませんが、このRAGというアプローチは、AIと企業ナレッジの最適な融合点として、今後のビジネスにおけるナレッジ活用の未来を切り拓いていくでしょう。
シーサイドでは、生成AIツールの活用に関するご相談も受け付けております。
お困りやご相談がありましたら、まずはお気軽にお問い合わせください。







